
AI Agent Performance Matters
The lightning-fast, intelligent retrieval layer every AI agent needs. Millisecond responses. Structured answers. No retrieval lag.
Lightning+ Delivers!
Real-Time
Agent Retrieval
Every AI application waits on retrieval — even single-step calls. The LLM always waits on retrieval. No matter how fast your model is, retrieval is on the critical path to every response. A fundamental latency constraint in any AI pipeline.

Built for Demanding
AI Workloads
Handles complex tasks effortlessly — fast, efficient, and always ready. Whether it’s large data sets, real-time analysis, or layered questions, Lightning+ delivers answers without delay.

Deploy
Anywhere
Deploy on cloud, on-prem, or at the edge. Runs as a lightweight Linux service in a Docker container. No lock-in. No proprietary formats. Just blazing-fast performance.
Lightning-Fast
Response
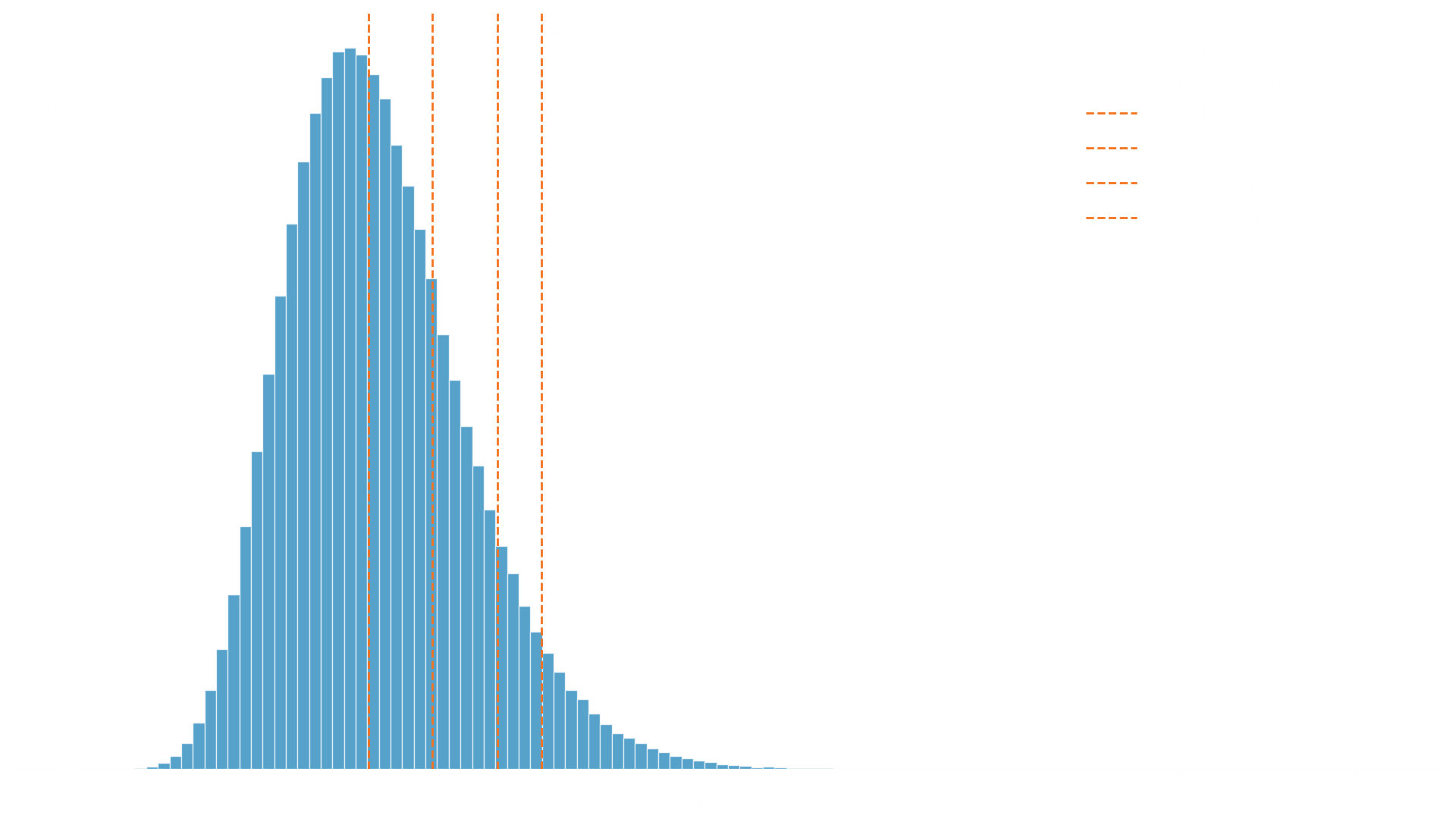
Agents need answers fast — and Lightning+ delivers. Our performance tests confirm sustained throughput of 60,000+ responses per minute, with latencies between 2ms and 40ms, even under continuous load. Built for speed and scale.
Benchmarks
RESULTS. Lightning+ completed 1,000,000 complex agent requests in under 20 minutes. Median latency: 25 ms.
Underlying Magic
How Lightning+ Delivers Speed
01
Agents Are the New Runtime
Agents connect models to knowledge and action. Whether using RAG or reasoning engines, they rely on fast, structured access to deliver accurate, dynamic results.
03
Slow Retrieval Increases Error & Cost
Latency leads to stale data, hallucinations, and missed context. It also drives up infrastructure costs — agents stall, retries multiply, and compute bills grow. Lightning+ solves both.
02
Fast Retrieval Makes Agents Truly Useful
Legacy systems weren’t built for Al workflows. Lightning+ removes the bottleneck with 10-100ms retrieval of live, structured results – powering real-time reasoning.
04
Speed Is the New Competitive Edge
In an agent-powered future, retrieval performance will define product success. Lightning+ gives you the edge – in accuracy, interactivity, and cost-efficiency.
Barbell Architecture
Wide connectivity on one end. High-speed, in-memory retrieval on the other.
01
Direct Data Access
Lightning+ connects to virtually any data source using zero-copy, parallel, multi-threaded streaming. No ingestion pipeline — data is streamed from files, APIs, or cloud storage and materialized as Arrow in-memory tables. Sources are created once and reused locally, minimizing cloud access and egress costs.
03
Powerful Query Engine
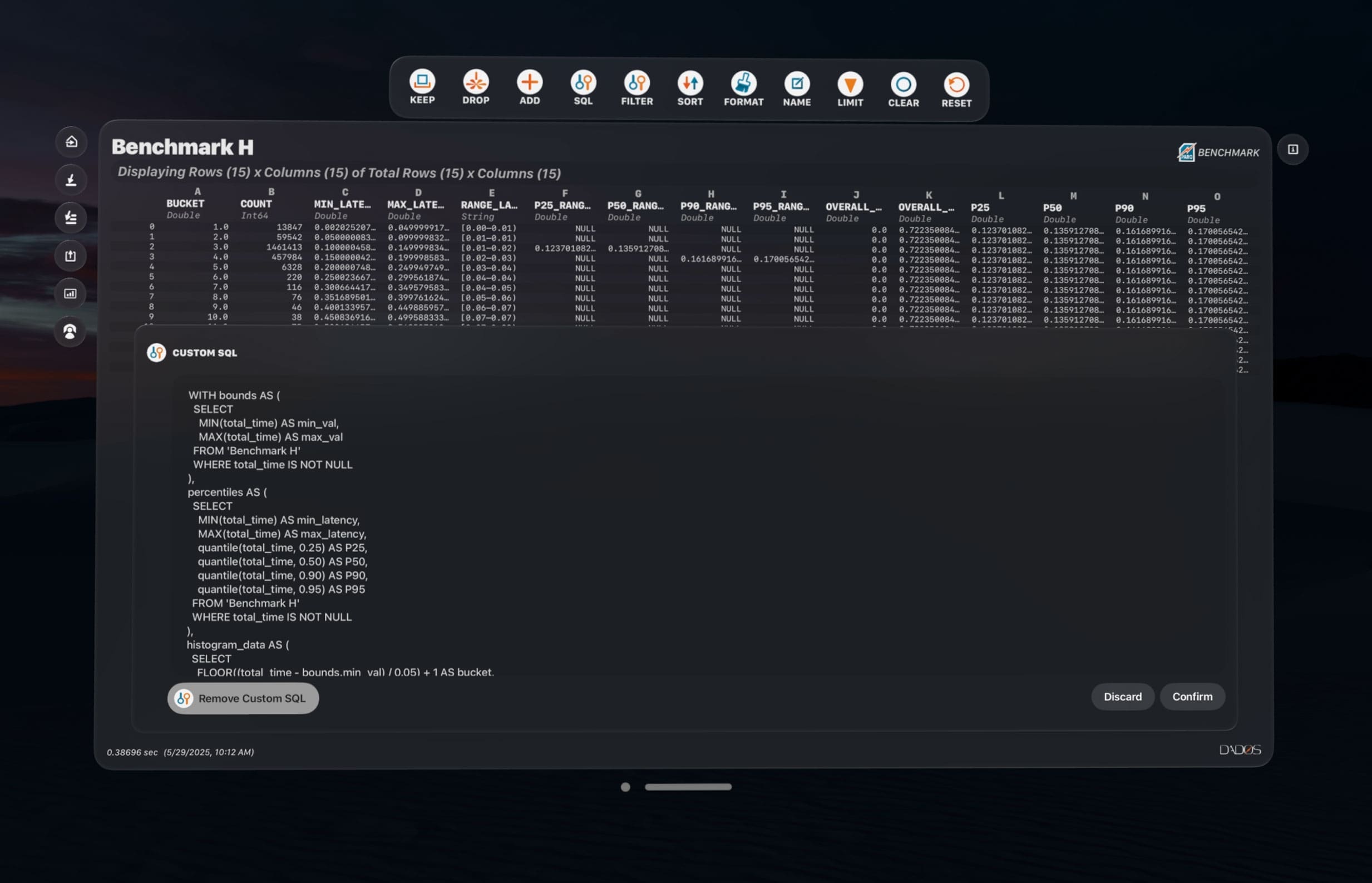
Built on DuckDB and Arrow, Lightning+ delivers a fully SQL-compliant engine with support for joins, unions, subqueries, window functions, filters, aggregations, and derived fields. It’s built for advanced logic, time-series operations, and multi-format data — processed at memory speed.
02
In-Memory Query Execution
Once in memory, data is queried with millisecond latency. Lightning+ uses a vectorized, parallel execution engine to run complex filters, joins, aggregations, and window functions — enabling real-time performance for AI agents and analytics workloads.
04
Seamless Output & Integration
Query results are returned instantly in Arrow, JSON, CSV or Markdown— ready for use by LLMs, APIs, or UI applications. Lightning+ fits directly into modern AI and analytics pipelines, delivering structured, typed results with no additional transformation required.
Core Differentiators
Features that set Lightning+ apart
01
Stateless execution
Every session is self-contained and in-memory.
Lightning+ leaves no data behind – ideal for
secure, ephemeral, and compliant deployments.
03
Real-Time Ready
Supports live sources like updated files and streaming APIs. Always delivers fresh, real-time data — not stale batch snapshots.
02
Session Reuse
Lightning+ connects to data sources, transfers the data once, and then disconnects — eliminating ongoing cloud consumption and significantly reducing egress costs. In-memory reuse means faster queries and lower bills.
04
Secure by Design
Lightning+ connects within your infrastructure —
no ingestion, no persistence, no vendor lock-in.
Works with VPCs, secure APIs, and local files.
Lightning+ Visual Data Workflow
Agents Need Data — And Data Is Messy
AI Agents are only as smart as the data they can access.
But real-world data is messy — scattered across systems, inconsistent in format, and constantly changing.
- It lives in APIs, spreadsheets, SQL databases, cloud storage, and remote files.
- It arrives in all shapes: CSV, JSON, Parquet, Markdown — sometimes all at once.
- It’s often nested, incomplete, and not ready for querying.
DataFrames Are the Center of the Big Data Universe
Modern AI workflows revolve around one thing: structured, queryable data. At the heart of it all is the DataFrame—the universal language of analytics, pipelines, and intelligent agents. But here’s the reality:
Tremendous effort goes into materializing data for use. Before a single query runs, someone has to connect, clean, normalize, and structure that data.
Lightning+ makes that process visual, repeatable, and blazing fast — so agents get the data they need without delay.

Connect. Clean. Structure.
Before an Agent can retrieve, reason, or act, the data must be connected, cleaned, and structured.Data Engineering Is the Missing Link. That’s where Lightning+ and DADOSlab come in. We give you the visual tools to:
01
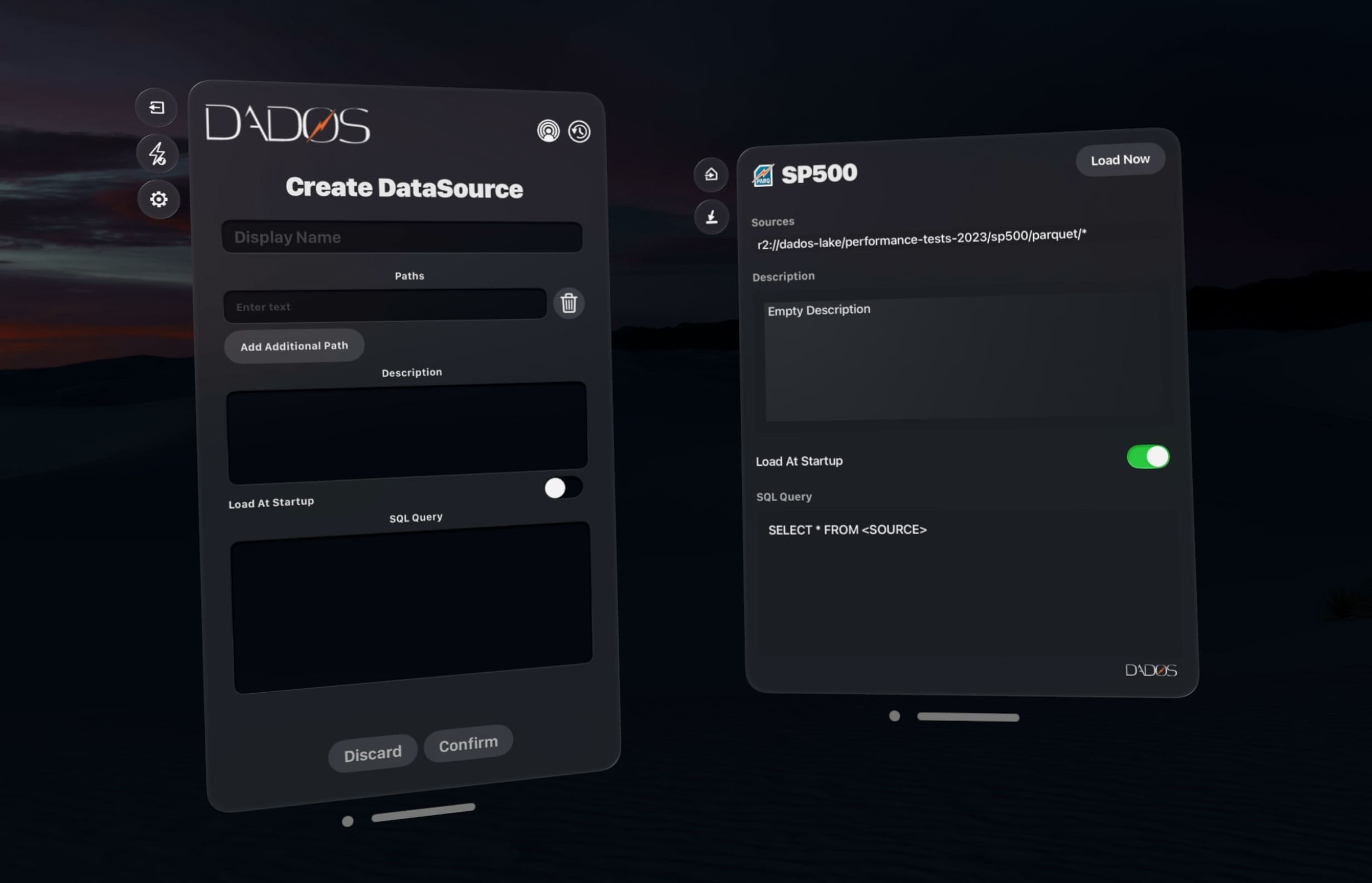
Create Data Sources
Connect to structured data wherever it lives — APIs, files, databases, or cloud buckets. From Parquet and JSON to SQL and REST — if it’s structured, we can connect.
02
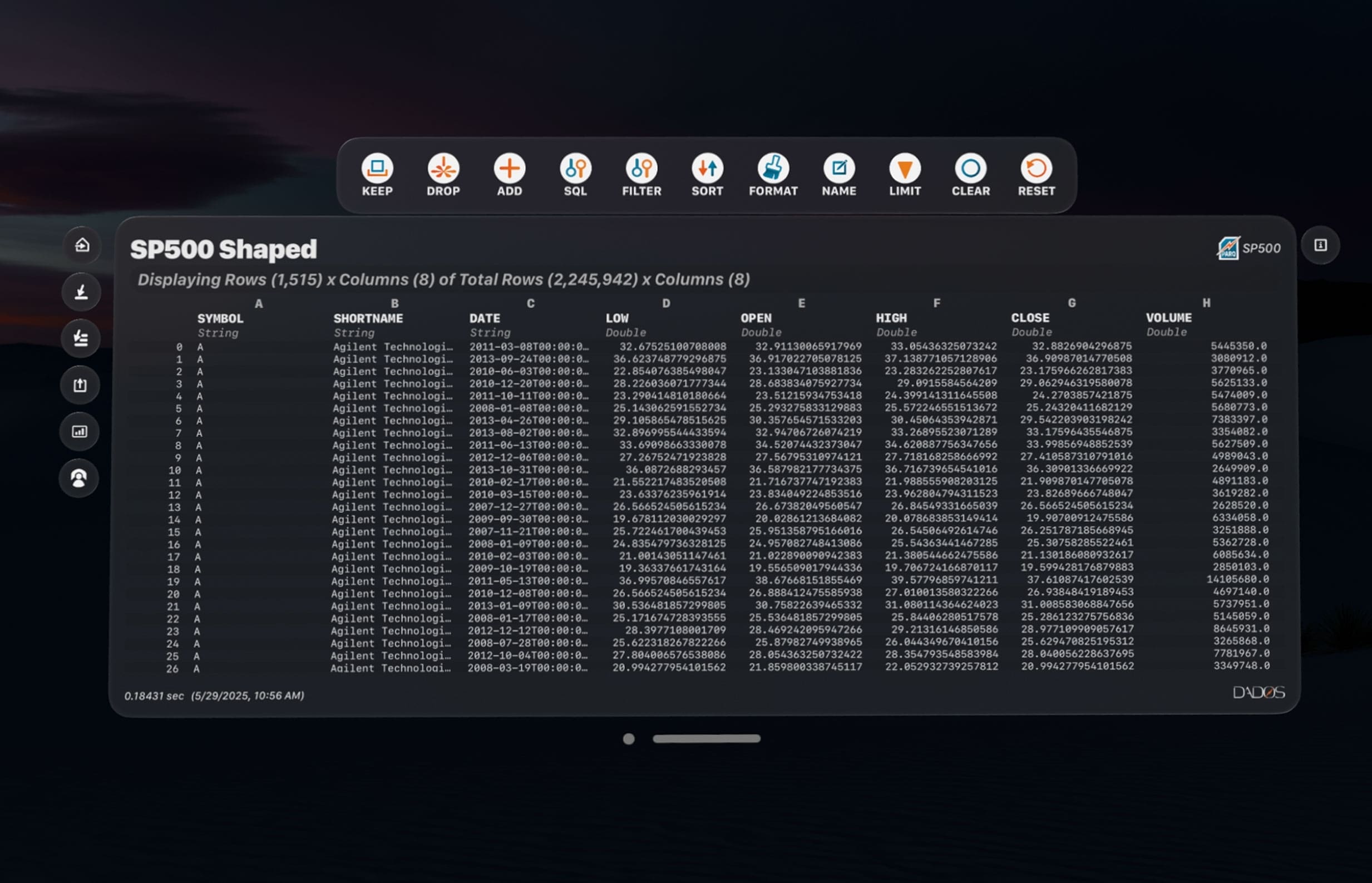
Create DataFrames
Data is instantly converted into a structured DataFrame with full schema. Columns are auto-detected, typed, and ready for analysis or querying.
03
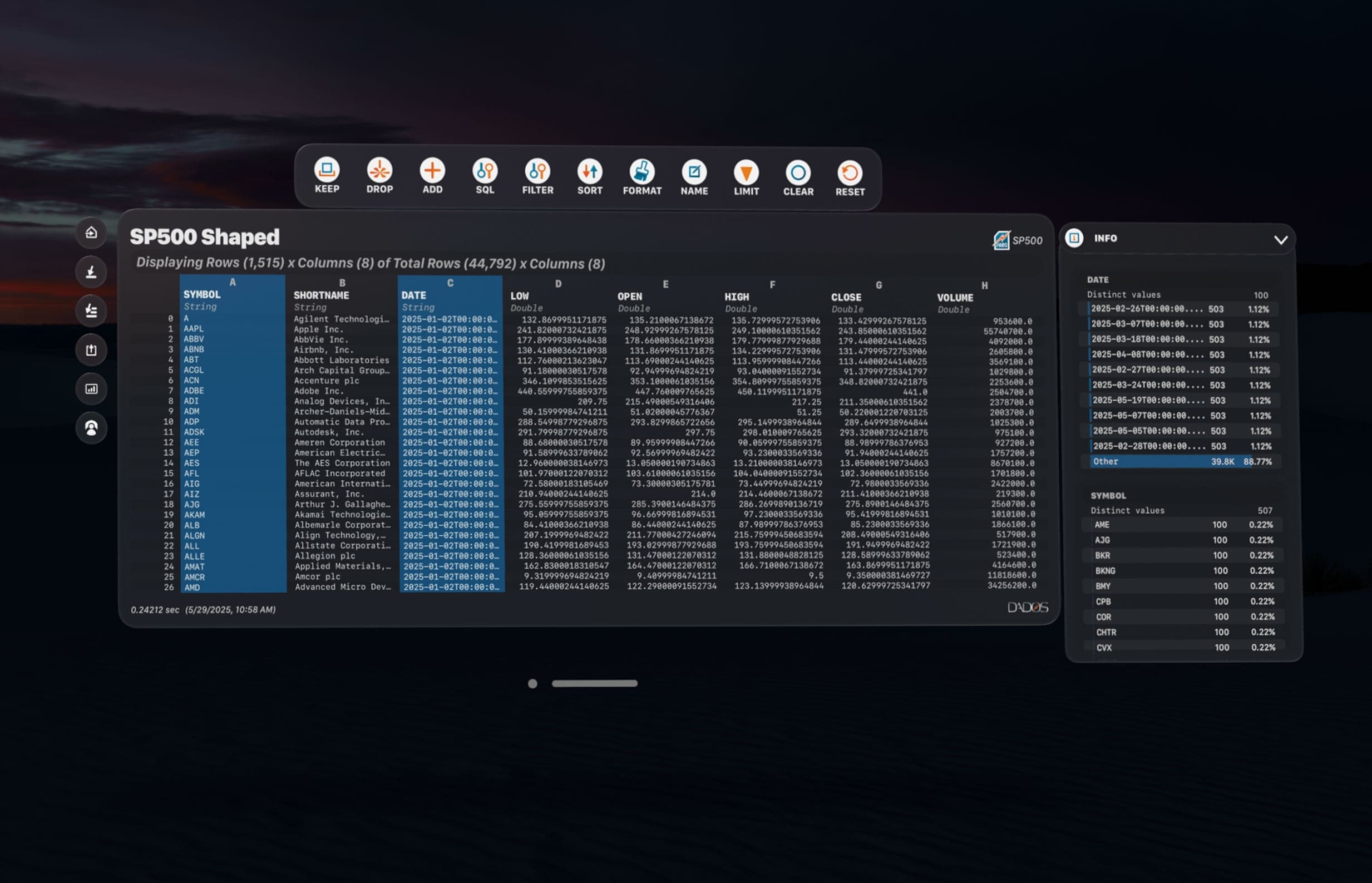
Shape DataFrames
Visually keep, drop, filter, sort, or add columns. No-code transformations with real-time feedback — or write custom SQL.
04
Combine + Join
Join DataFrames, union datasets, or create derived columns. Link across sources to build richer, multi-table views.

05
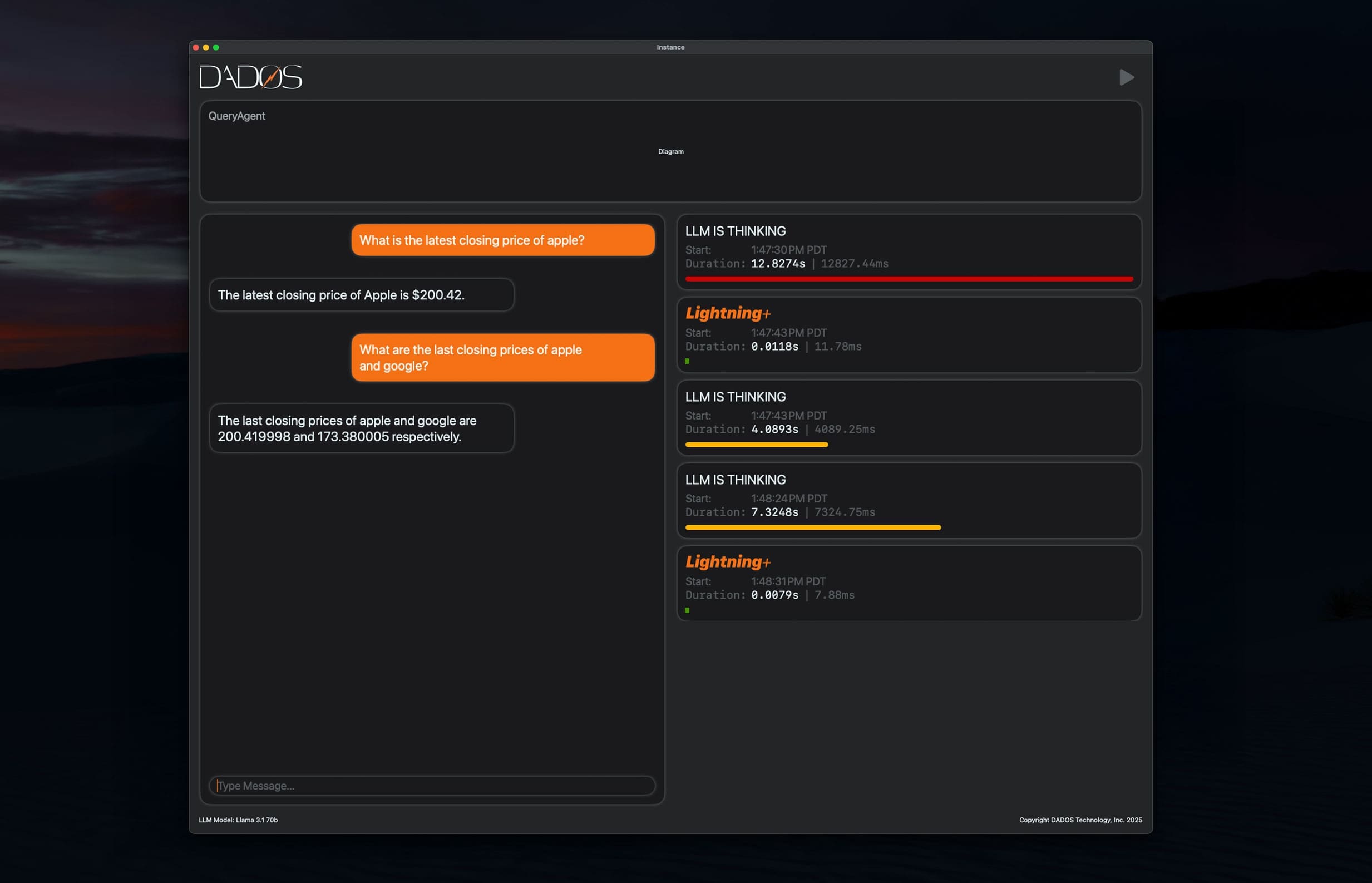
Query + Retrieve
Query DataFrames with SQL, Python, or AI Agents — with millisecond response times. Structured answers stream directly to agents in Arrow, JSON, CSV, or Markdown.
06
Deploy
Deploy structured DataFrames to memory — instantly queryable by agents and applications. No ingestion, no delay — your data is live and ready.
ABOUT
DADOS Technology builds infrastructure for real-time, AI-native data retrieval. Our flagship product, Lightning+, is a high-performance, in-memory data server that delivers structured answers to AI agents in milliseconds — enabling them to retrieve, reason, and act without delay. DADOS began by building immersive spatial analytics for the Apple Vision Pro. But as enterprise AI adoption accelerated, we saw a greater opportunity: retrieval performance had become the bottleneck — and the cost of cloud-based solutions was scaling out of control. Dashboards could wait — agents could not.
We pivoted to focus on what matters most: speed, structure, scale — and cost control. Lightning+ was born out of this insight: a fast, local, Docker-deployable data server that speaks DuckDB, streams Parquet and Arrow, and handles thousands of requests per second without cloud egress fees or consumption-based pricing.
Founded by Ken Gardner (CEO) (ReportSmith, Sagent Technology (IPO), SOASTA, conDati) and Luke Gardner, (CTO), DADOS is on a mission to make real-time AI retrieval radically faster, more open, and economically sustainable.